
本文中回顾数据结构中,各种队列的特性。
预备
队列,是一种先进先出(FIFO)的线性表,一般来说会使用链表或者数组来实现它。
队列被允许从后端(rear)插入(insert)新元素,称作入列(push,enqueue);而从前端(front)弹出(pop)元素,称作出列(pop,dequeue)。
学术上说它和堆栈常常被同时提起,因为堆栈与队列几乎一摸一样,除了出栈时也在后端弹出元素,从而构成了后进先出(LIFO)的数据结构。
古典的单向链表/单向队列
单向链表表示的队列,出列时必须遍历整个链表,直至链尾的前一位,然后摘除链尾来实现出列操作。
毫无疑问,这一定是代价很高的。
但这种方案的优势在于任何时候任何人都能够随手写得出来。也就是说,它是最具备可手撸性的一种实现方案,虽然出列代价较高,但对于相当多的场景来说那点代价 CPU 根本不当作是事。
双向链表/双向队列
双向链表的好处是在链表头尾的操作都是 O(1) 的,代价极低,可以视作毫无代价。但这是用额外的两个指针的空间代价来达成的。对于像 std::deque<long> 这样的双向链表来说,每个链表元素的数据部分(payload)需要 8 bytes,而附着在 payload 上的指针则需要 16 bytes(典型的 64bit 计算时),相当于说超出数据实体两倍的代价,不可謂不昂贵。幸而通常的实践场景中很少会有这样的实践需求,往往更多的是一个 payload 的实体 struct 可能需要数百 bytes 甚至更多,这时候 16 bytes 就不算太起眼了。
双向链表结构的手写,难点在于指针的同步修改,正确指向。
对于高频交易场景来说,双向链表的指针维护操作是导致锁开销的典型瓶颈,所以需要下力气研究和解决锁问题。
一般来说在现实世界中大家都是借助于 STL 来实现队列算法及其应用的。典型的例子是通过 deque:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <iostream>
#include <deque>
int main()
{
// 创建容纳整数的 deque
std::deque<int> d{};
// 约定 push_back 为入列操作
d.push_back(13);
d.push_back(25);
d.push_back(7);
d.push_back(2);
// 约定 pop_front 为出列操作
auto tmp = d.pop_front();
std::cout << "FRONT: " << tmp << '\n';
// 迭代并打印 deque 的值
for(int n : d) {
std::cout << n << '\n';
}
}
得益于 deque 的强健的基础能力,我们实际上可以得到一个工程强度的有效的队列模板类。
同时,deque 也可以被毫无代价地实现强健的 Stack 数据结构,仅仅是将出栈操作从上文的 pop_front 改为 pop_back() 即可。
所以,deque 的强大可见一斑。
不过,无论如何,我们有必要手写一份来完成自己的理解。在下面我们简单地实现了一份理论上的典型队列方案:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
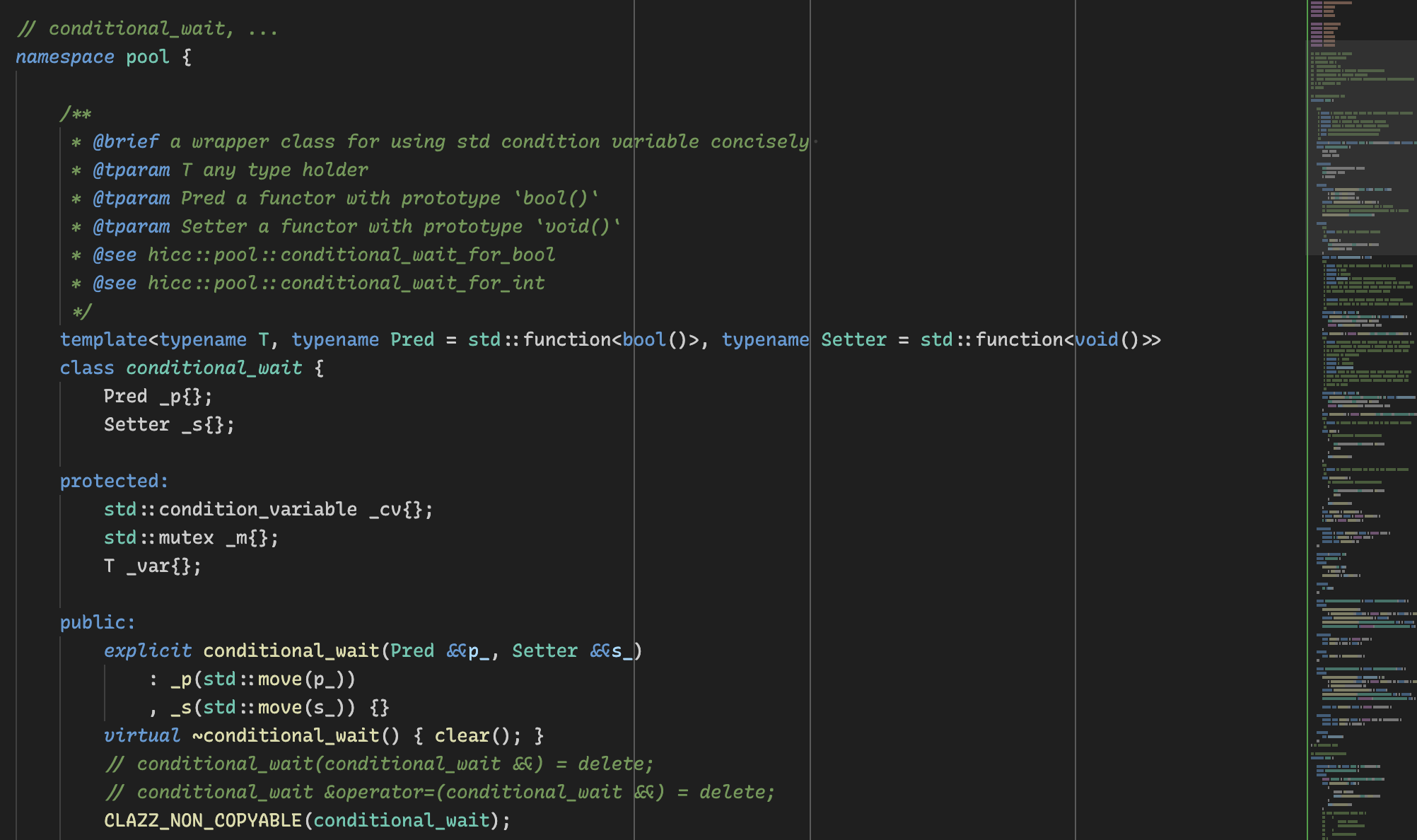
template<class T>
class ti_queue {
public:
struct element {
T _data;
element *_last;
element *_next;
};
public:
ti_queue() {
_head = new element;
_tail = new element;
_head->_next = _tail;
_tail->_last = _head;
}
~ti_queue() {
auto *p = _head;
while (p != nullptr) {
auto *t = p;
p = p->_next;
delete t;
}
}
void push(T const &data) {
auto h = _tail->_last;
auto *ptr = new element{data, h, _tail};
_tail->_last = ptr;
h->_next = ptr;
}
T pop() {
auto p = _head->_next;
if (p == _tail) {
return T{};
}
p->_last->_next = p->_next;
p->_next->_last = p->_last;
T t = p->_data;
delete p;
return t;
}
bool empty() const { return _tail->_last == _head; }
T const &peek() const {
if (empty()) return _tail->_data;
return _tail->_last->_data;
}
private:
element *_head{};
element *_tail{};
};
这是一份不采用智能指针的实现。因为智能指针在这里只有坏处没有好处。然而这就会使得这份实现显得低级,很有趣吧,现代 C++ 在很多时候其实是扭曲了的,它虽然很现代,很时髦,但也很脱了裤子放屁。
在这份实现中有一个重要的约定:我们认为你在提供 T 的具现类型时,你会隐含地约束零值初始化的 T 示例代表着空元素。所以当你 pop/peek 得到一个 T 实例时,如果它是零值将代表着队列为空。
所以我们的测试片段为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int main() {
std::cout << '\n' << "queue: ";
bet::ti_queue<int> tiq;
tiq.push(31);
tiq.push(17);
tiq.push(19);
tiq.push(73);
auto tmp = tiq.pop();
std::cout << tmp;
while (!tiq.empty()) {
tmp = tiq.pop();
std::cout << ',' << tmp;
}
std::cout << '\n';
}
其结果应该形如这样:
1
queue: 31,17,19,73
OK,继续我们的思考线路:
检测队列有否为空很重要,你不可能无代价地避免空访问,因为这是数据结构本身的特性决定的。而在具体实现方面,上面之所以要做出那样的约定,是因为我们没有使用指针方案来存储 T,所以你需要检查 pop/peek 得到的 T 实例是否为空元素。或者,你在 pop/peek() 之前首先采用 empty() 进行队列非空判断。
如果采用指针存储方案的话,你可以顺理成章地检查 pop/peek 返回值是否 nullptr,这其实是 C/C++98 时代的典型实现方案。
如果是在 C++11 之后,尽管我们的实现有上述约定,但你也可以通过给 T 实例化为 std::shared_ptr<Real> 的方式来建立一个智能指针的缓冲层,因此你可以判断该指针的非空性来鉴别返回值的非空性。
借助于共享指针的强力特性,很多时候我们无需在做容器实现时考虑太多的元素如何存储的问题,因为模板的一个重要能力就是透明地引入中间层来提供额外的供给能力。这种时候,在这个例子里,中间层的智能指针包装实际上提供了一种装饰器的设计模式运用机制。
所以,
我们认为,在容器等数据结构等实现部分,如果有可能,你应该负起责来,自行处理 C++/C 指针的各种运算,保证你的实现边界之内没有泄漏问题。这样做的好处在于你的实现将会非常可读可维护,因为它通常能够和理论上的数据结构的实现近似于等价,如同我们上面的实现一样。
然而,如果你的目标是在面向两个目标时则例外了:第一个目标是工程性的高性能线程安全性要求,此时应该加上的锁、优化则取决于具体实现;第二个目标是用户的使用简便性,很显然让用户直接具现他们的 T 而不是 shared_ptr<T> 是绝对有助于用户的使用简便性的,那么你就可能要在精打细算和借助智能指针方面做个选择了。
环形队列
此前,我其实在 Golang 针对高频交易提出了一种无锁环形队列的实现方案,在那里使用了一种程序员直觉化的代码编写方法及直觉化的算法设计思路。事实上我个人偏好于那种直觉化的算法设计思路,我讨厌搞委托交易,像 Spring framework 这样的框架,在做无论什么的集成的时候如同脱了裤子放屁一般的老奶奶裹脚布似的做法,我鄙视之,所以我现在根本没兴趣讨论 Java 的任何事情,这是被我判定了不值得的一种技术体系。
不过,RxJava 的思路是符合我的审美观的。这才是对世界做抽象的正确态度。
那种顽固地拿着 XML 搞出一个庞大的 shit 堆的方法,我只能是表示敬而远之。不但是 Java 的多数玩意如此地垃圾,.NET 画界面 XAML,macOS XCode 画界面的 Storyboard 统统都是毫无疑问的垃圾。任何和 XML 紧密捆绑的东西,没说的,都是在创造垃圾。
那是一种将任何事情复杂化的思维模式,我拒绝的正是如此这般明显愚蠢的模式。
所以我这样的人,一边不爽 Golang 的简陋,一边不也还是投入其怀抱了吗——就因为它能够极低代价的 ELF 化啊。程序员要干的事情就是简化这个世界。创造垃圾这样的事是干不得的。
所以,环形队列在理论研究层面看,实际上就是一个数组,它是固定大小的,而后我们将其首尾相接(通过 put-pointer 和 get-pointer 自动回绕的方式),形成了抽象层面上的环形状态。它的特点在于,当排除了分配每个元素的代价之后,它可以通过自己的固定缓冲区的特点来去除对象入列和出列时的潜在可能的复制开销。
关于这一点,即使是充分利用 C++11 甚至 C++17 的现代语法,在借用 STL 来实现队列的时候,你可能也往往无法避免出列时的复制开销。如果考虑到高频交易场景下想要避免锁代价的影响的话,往往你可能连入列时的额外开销也无法避免——只不过,很多时候锁的代价更高过内存分配已经内存复制的总线级代价,所以我们不得不两害相权取其轻罢了。
为了解决这种特定的问题,一种方案是通过环形队列来避免内存分配问题;另一种则是自行构造自己的队列模板,通过专门的设计和实现来取得内存分配、内存复制与读写访问、CPU Cache 等层面的锁的问题等等的平衡。
再有一种方案,那就简单了:用指针吧。鉴于 C++11 之后用裸指针被认为是跟不上时代的表现,所以:用智能指针吧。借助智能指针的移动语义或共享计数值技术,通常可以较低代价地避免内存反复频繁分配以及内存复制带来的额外开销问题。这种方案是有一点投机取巧,但是语言的基础设施本就应该提供给程序员以这样的能力。反过来思考,如果一个程序员根本经受不了 C 指针的蹂躏的话,他也不配被称作程序员。话说今天这话也很没意思,阿猫阿狗都是程序员的——劣币正在驱逐良币。
应用
由于环形队列是固定大小的,所以它极其适合这样的场景:数据采样工具,或者遥测场景。在数据采样的场景,常常需要的是最最近几十条记录进行数学分析。当使用环形队列来做相应的数据缓冲时,老的数据不断随着插入指针的推进而被覆盖掉,所以在取出指针一侧总是最新的 N 条记录,N 是环形队列的预设大小。于是分析器可以面对这个环形队列顺利地提取到最新 N 条记录用于计算和分析。
除此而外,我们还可以让环形队列的插入行为是非覆盖的,于是当队列满时,插入操作就会在队尾被阻塞,这是另一种环形队列的应用方式。
下几期我将可能会考虑实现一份 C++ 版本的环形队列,但这次可能不会做高频版了,大约只会做适合毫秒级例如典型工业 TCP 交易的版本。
Conclusion
队列这种数据结构,总体上来说非常简单,也不会牵涉到高深的数学证明,所以实现一个队列往往会是初学者上手编程的好题目。
留下评论